感触很深的一个场景~~

MLP 简介#
线性模型有许多限制 (很显然,这里就不讲了)
可以在网络中加入隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系。最简单的方法是将许多全连接层堆叠在一起,每一层都输出到上面的层,直到生成最后的输出。我们可以把前 L−1 层看作表示,把最后一层看作线性预测器。
这种架构通常称为 多层感知机(multilayer perceptron)即MLP
由于仿射函数的复合还是仿射函数(显然),所以简单堆叠更多线性层而不做其他变换 对于非线性的学习 是毫无意义的,反而徒增参数量(虽然说并非完全无意义 hh)。
MLP 的优势在于在仿射变换之后对每个隐藏单元应用非线性的 激活函数 activation function σ。激活函数的输出被称为 活性值 activations。有了激活函数,一般就不可能再将我们的多层感知机退化成线性模型。
MLP 的结构#
无需多言!
HO=σ(XW(1)+b(1)),=HW(2)+b(2).
对每个隐藏层都做一次过一次非线性的激活函数后,隐藏层堆起来就有其意义了(学习更复杂的非线性关系,从而具有更强大的表达能力)。
H(1)H(2)=σ1(XW(1)+b(1))=σ2(H(1)W(2)+b(2))⋯
隐藏层可以加广 / 变深,但得有个取舍 (略)
激活函数们#
第一个出场的是大名鼎鼎的 ReLU 函数,虽然它看起来非常简单,但确实是最广泛使用的激活函数之一。
非常地简单粗暴啊,遇到负值直接变 0,遇到正值就照抄。
ReLU(x)=max(x,0).
函数图像从略
但有一个问题,它在 x=0 的时候的导数值有一个突变(这就非常烦人了,事实上一切边界条件都很烦人),于是我们默认 0 处的导数值为 0 hh,直接采取无所谓的态度。
有点像电路里的整流二极管(信号要么通过,要么阻断)。更重要的是它解决了神经网络的梯度消失问题()。
“那么可不可以网开一面,保留一小部分信号通过呢?”
于是有了它的改进版 pReLU:
pReLU(x)=max(0,x)+αmin(0,x).
第二个出场的是 sigmoid 函数,sigmoid:R→(0,1)
sigmoid(x)=1+exp(−x)1.

然而,sigmoid 在隐藏层中已经较少使用, 它在大部分时候被更简单、更容易训练的 ReLU 所取代。 循环神经网络中利用 sigmoid 单元来控制时序信息流的架构。当输入接近 0 时,sigmoid 函数接近线性变换。
dxdsigmoid(x)=(1+exp(−x))2exp(−x)=sigmoid(x)(1−sigmoid(x)).
(这倒是一个不错的性质)
最后一个介绍的是 tanh 函数
tanh(x)=1+exp(−2x)1−exp(−2x).
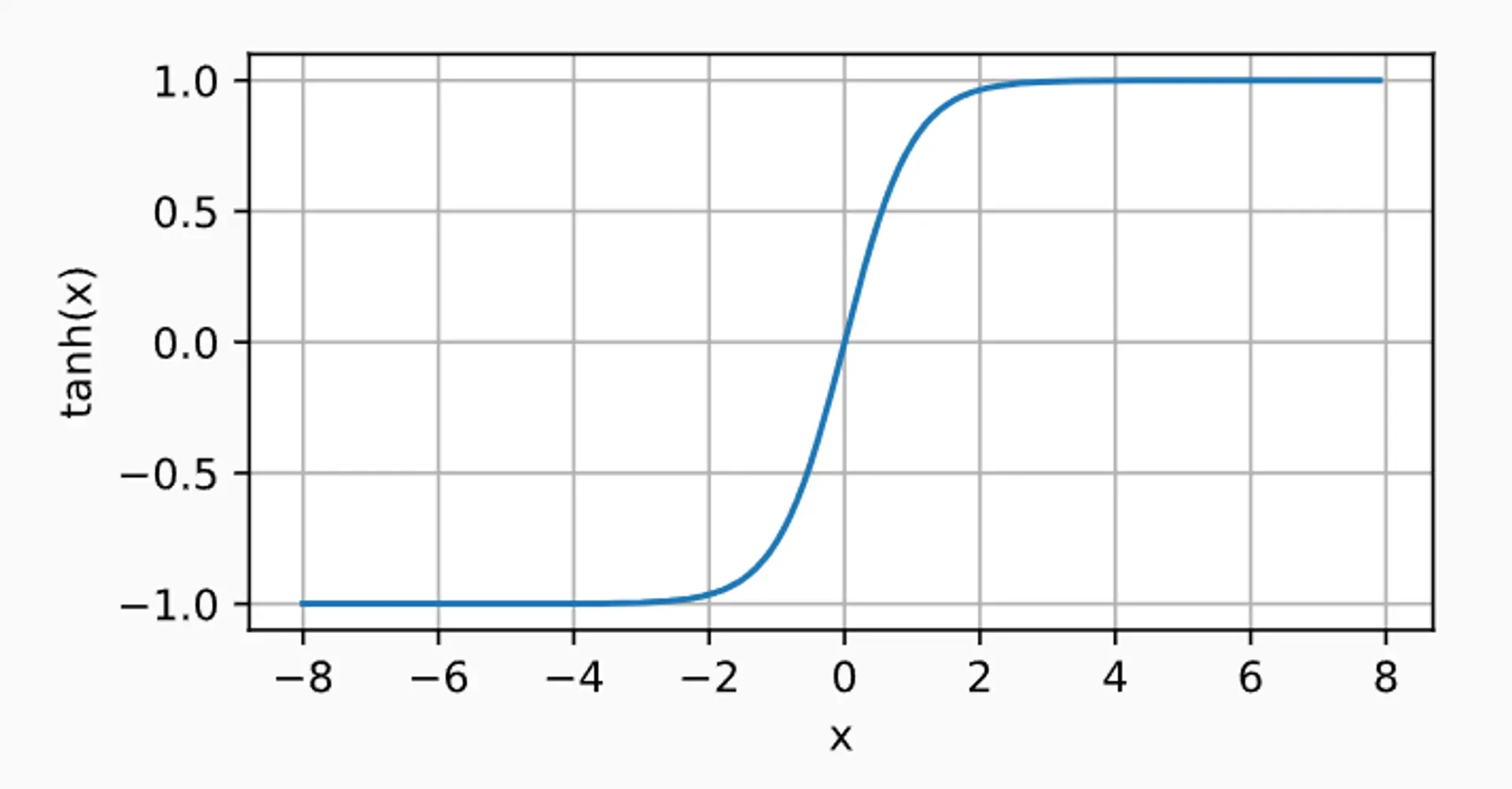
dxdtanh(x)=1−tanh2(x).
(这也是一个不错的性质)
(虚假的)结束语#
当然会再回头补充,但就先写到这里,代码部分想另外开一个栏))
Bye~